
TensorRT is a high-speed inference library developed by NVIDIA. It speeds up already trained deep learning models by applying various optimizations on the models.
The following article focuses on giving a simple overview of such optimizations along with a small demo showing the speed-up achieved.
The first part gives an overview listing out the advantages of using this library without getting into too much technical details. While the second part details a quick hands-on procedure to test the performance.
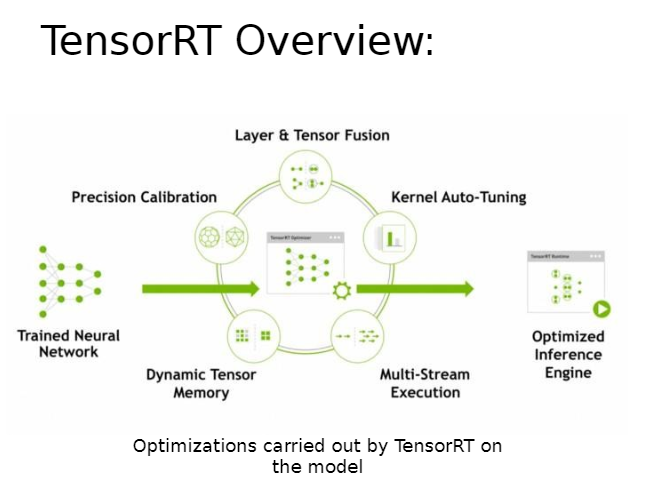
Layer and Tensor Fusion
Avoids multiple kernel creation/execution
Two or more layers are combined to form one layer. When a model runs on GPU, each layer is executed in a new CUDA kernel. Depending on the layers, the overhead of launching separate kernels could be higher than the computation itself. So by fusing two or more layers, we can avoid creating and launching multiple CUDA kernels.
Precision Calibration
Uses the efficient precision for a tensor
Once the neural network model has been trained, the weights/outputs of certain layers may span a limited range and would not need the full range offered by FP32. TensorRT can identify such weights/outputs and convert them to FP16 or even INT8. Thus speeding up calculation and using less memory.
Multi-Stream Execution
Exploits parallelism
CUDA kernels run in a stream on a GPU. If no optimization is performed on the stream selection/creation, all the kernels will be launched on a single stream, making it a serial execution. Using TensorRT, parallelism can be exploited by launching independent CUDA kernels in separate streams.
Dynamic Tensor
Re-uses allocated GPU memory
TensorRT identifies chances of memory re-use for tensors, thus avoiding the overhead of memory re-allocation. This in turns reduces latency and contributes to the inference speed- up.
Kernel Auto-Tuning
Cherry-picks kernel for a target platform/GPU
Various common deep learning kernels perform differently depending on the target platform, the model is executed upon. TensorRT identifies the best implementation of a kernel from a set of implementations for a specific target platform/GPU.
So what are the pros and cons of using TensorRT?
Pros: High-speed Inference
Cons: Cannot train a network
Being an Inference library, TensorRT cannot be used to train a network. It is commonly used when deploying a final trained network.
Now that we have seen the advantages of using TensorRT, lets dive into some hands-on experience and see it in action!
First let us set-up some requirements (skip the bits which are already installed).
Simple Demo
Install nvidia drivers:
To list available nvidia drivers:
$ ubuntu-drivers devicesTo install recommended drivers
$ sudo ubuntu-drivers autoinstallInstall nvidia-docker:
Please Note: With the release of Docker 19.03, usage of nvidia- docker2 packages are deprecated since NVIDIA GPUs are now natively supported as devices in the Docker runtime. So you can skip the next step if you have a docker version ≥19.03
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit
$ sudo apt-get install nvidia-docker2
$ sudo systemctl restart docker
Install CUDA Toolkit 11.0:
$ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin
$ sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600
$ wget http://developer.download.nvidia.com/compute/cuda/11.0.2/local_installers/cuda-repo- ubuntu1804-11-0-local_11.0.2-450.51.05-1_amd64.deb
$ sudo dpkg -i cuda-repo-ubuntu1804-11-0- local_11.0.2-450.51.05-1_amd64.deb
$ sudo apt-key add /var/cuda-repo-ubuntu1804-11-0- local/7fa2af80.pub
$ sudo apt-get update
$ sudo apt-get -y install cudaPull TensorRT docker file:
$ docker pull nvcr.io/nvidia/tensorrt:20.07.1-py3Run docker container (You might need to reboot once if it fails):
$ sudo nvidia-docker run -id — name tensorrt_demo nvcr.io/nvidia/tensorrt:20.07.1-py3Enter the docker container:
$ sudo nvidia-docker exec -it docker_id bash(You can find docker_id by running: sudo nvidia-docker ps -a)
We will use torch2trt module to convert torch model to TensorRT.
Please Note that NVIDIA does provide Python API to access the C++ TensorRT API. And the most performance benefits can be achieved by using the NVIDIA APIs. But for our case we will keep it simple and use torch2trt to compare the performance.
Clone torch2trt:
torch2trt is a PyTorch to TensorRT converter which utilizes the TensorRT Python API
$ git clone https://github.com/NVIDIA-AI- IOT/torch2trt.git
$ cd torch2trtInstall torch:
$ pip3 install torch torchvision termcolorRun torch vs TensorRT benchmarks:
$ ./test.sh TEST_OUTPUT.md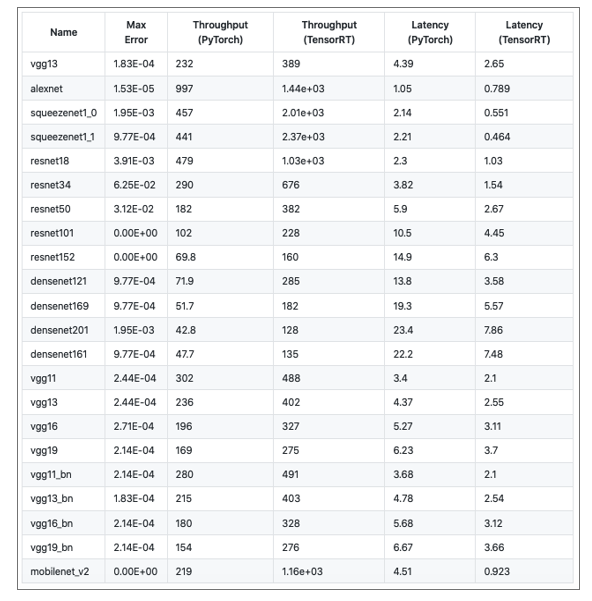
As seen above, TensorRT outperforms Inference performance by almost 2x — 3x times.







